Simulating observations with MUSTANG-2¶
MUSTANG-2 is a bolometric array on the Green Bank Telescope. In this notebook we simulate an observation of a galactic cluster.
[1]:
import maria
import scipy as sp
import numpy as np
import matplotlib.pyplot as plt
map_filename = maria.io.fetch("maps/cluster.fits")
# load in the map from a fits file
input_map = maria.map.read_fits(
nu=150,
filename=map_filename, # filename
resolution=8.714e-05, # pixel size in degrees
index=0, # index for fits file
center=(150, 10), # position in the sky
units="Jy/pixel", # Units of the input map
)
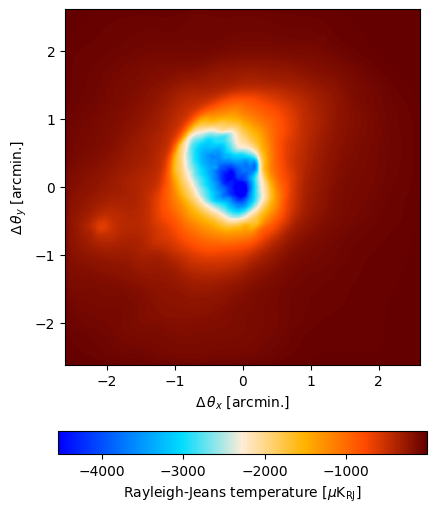
input_map.data *= 1e1
input_map.to(units="uK_RJ").plot()
Downloading https://github.com/thomaswmorris/maria-data/raw/master/maps/cluster.fits: 100%|██████████| 4.00M/4.00M [00:00<00:00, 179MB/s]
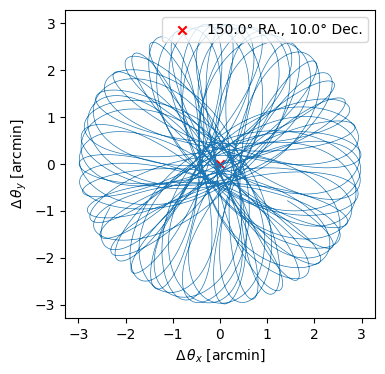
Observing strategy¶
Below we define the observing strategy containing the duration, integration time, read out rate, and pointing center
[2]:
# load the map into maria
plan = maria.get_plan(
scan_pattern="daisy", # scanning pattern
scan_options={"radius": 0.05, "speed": 0.01}, # in degrees
duration=1200, # integration time in seconds
sample_rate=50, # in Hz
scan_center=(150, 10), # position in the sky
frame="ra_dec",
)
plan.plot()
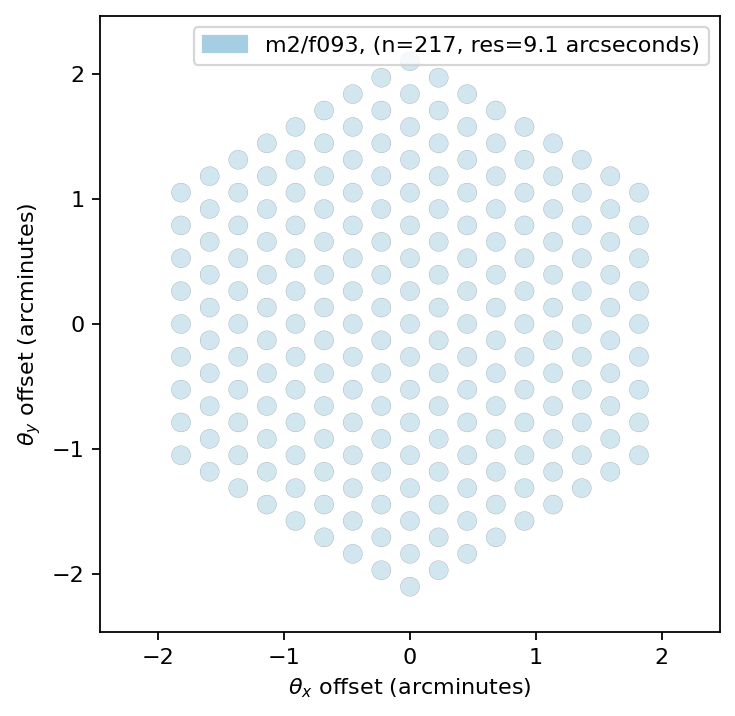
Define instrument¶
We have configuration files in place to mimic typical telescopes and instruments. To run a MUSTANG-2 like observations, simply initialize the instrument as follows. Other tutorials will go into more detail on how to adjust it to test out how telescope designs affect the recovered signal.
[3]:
instrument = maria.get_instrument("MUSTANG-2")
We can plot the instruments which will show the location of the detectors in the FoV with their diffrection limited beam size. The detectors for MUSTANG-2 are spaced at 2 f-lambda.
[4]:
instrument.plot()
Initialize the simulation¶
The simulation class combines all the components into one.
[5]:
sim = maria.Simulation(
instrument,
plan=plan,
site="green_bank",
map=input_map,
atmosphere="2d",
cmb="generate",
)
Downloading https://github.com/thomaswmorris/maria-data/raw/master/atmosphere/spectra/am/green_bank.h5: 100%|██████████| 2.31M/2.31M [00:00<00:00, 167MB/s]
Downloading https://github.com/thomaswmorris/maria-data/raw/master/atmosphere/weather/era5/green_bank.h5: 100%|██████████| 6.06M/6.06M [00:00<00:00, 193MB/s]
Constructing atmosphere: 100%|██████████| 6/6 [00:07<00:00, 1.26s/it]
Generating CMB (nside=1024): 0%| | 0/1 [00:00<?, ?it/s]
Downloading https://github.com/thomaswmorris/maria-data/raw/master/cmb/spectra/planck.csv: 293kB [00:00, 62.8MB/s]
Generating CMB (nside=1024): 100%|██████████| 1/1 [00:06<00:00, 6.07s/it]
Obtaining time-ordered data (TODs)¶
To acquire time-ordered data (TODs), you only need to run the script. The TOD object contains time stamps, coordinates (in RA and Dec), and the intensity of each scan for every detector. The intensity units are expressed in power can be converted to surface brightness temperature units: Kelvin Rayleigh-Jeans (Even if the input map is given in Jy/pixel. We convert the units under the hood).
[6]:
tod = sim.run()
Generating turbulence: 100%|██████████| 6/6 [00:00<00:00, 31.22it/s]
Sampling turbulence: 100%|██████████| 6/6 [00:01<00:00, 3.91it/s]
Computing atmospheric emission: 100%|██████████| 1/1 [00:02<00:00, 2.24s/it, band=m2/f093]
Sampling CMB: 100%|██████████| 1/1 [00:08<00:00, 8.83s/it, band=m2/f093]
Sampling map: 100%|██████████| 1/1 [00:07<00:00, 7.84s/it, band=m2/f093]
Generating noise: 100%|██████████| 1/1 [00:00<00:00, 1.04it/s, band=m2/f093]
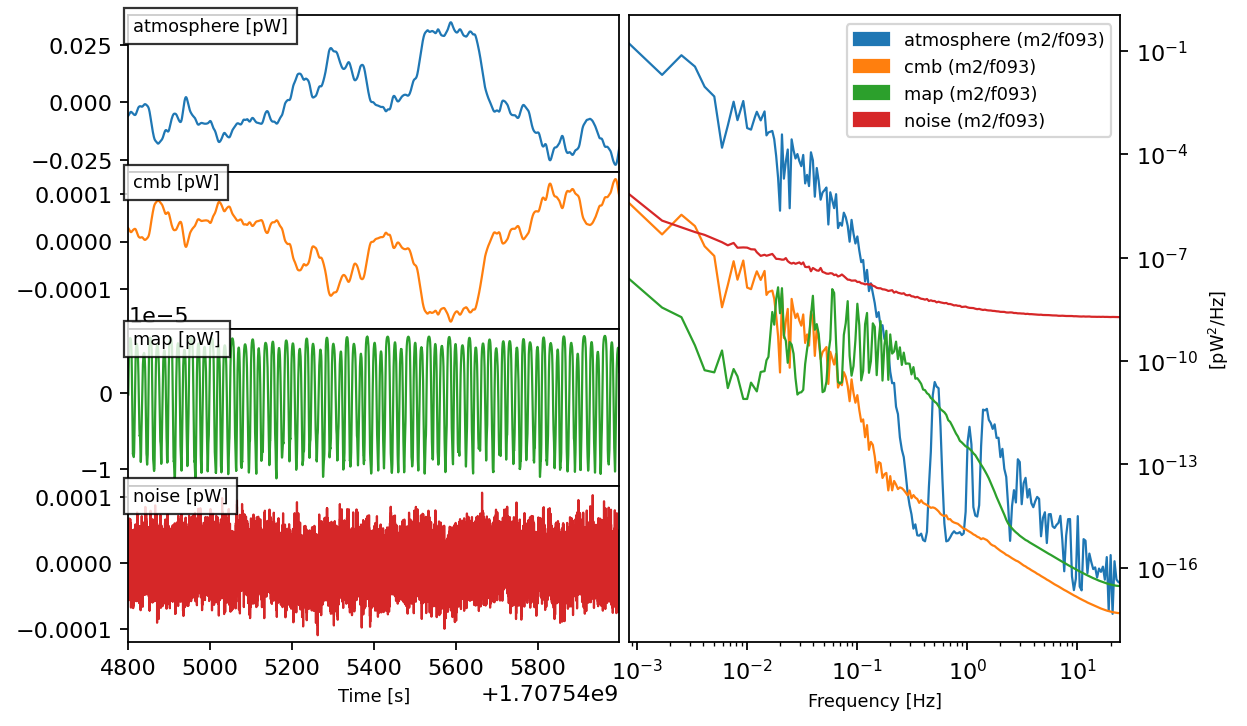
Useful visualizations:¶
Now, let’s visualize the TODS. The figure shows the mean powerspectra and a time series of the observations.
[7]:
tod.plot()
Mapping the TODs¶
To transform the TODs into images, you’ll require a mapper. While there is an option to use your own mapper, we have also implemented one for your convenience. This built-in mapper follows a straightforward approach: it removes the common mode over all detectors (the atmosphere if you scan fast enough), then detrends and optionally Fourier filters the time-streams to remove any noise smaller than the resolution of the dish. Then, the mapper bins the TOD on the specified grid. Notably, the mapper is designed to effectively eliminate correlated atmospheric noise among different scans, thereby increasing SNR of the output map.
An example of how to run the mapper on the TOD is as follows:
[8]:
from maria.mappers import BinMapper
mapper = BinMapper(
center=(150, 10),
frame="ra_dec",
width=0.1,
height=0.1,
resolution=2e-4,
tod_preprocessing={
"window": {"name": "hamming"},
"remove_modes": {"modes_to_remove": [0]},
"remove_spline": {"knot_spacing": 10},
},
map_postprocessing={
"gaussian_filter": {"sigma": 1},
"median_filter": {"size": 1},
},
units="uK_RJ",
)
mapper.add_tods(tod)
output_map = mapper.run()
2025-02-09 01:09:45.941 INFO: Ran mapper for band m2/f093 in 12.3 s.
Visualizing the maps¶
As interesting as the detector setup, power spectra, and time series are, intuitively we think in the image plane. so let’s visualize it!
[9]:
output_map.plot()
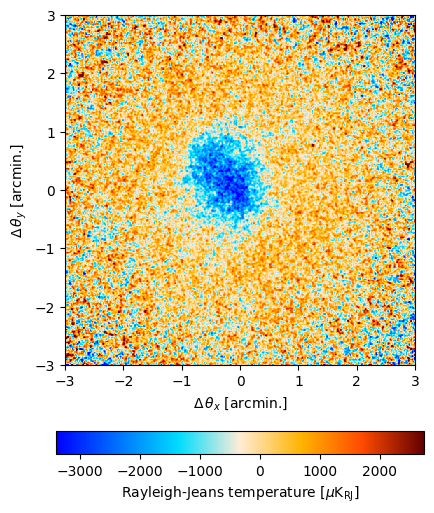
You can also save the map to a fits file. Here, we recover the units in which the map was initially specified in.
[10]:
output_map.to_fits("/tmp/simulated_map.fits")